Applicable versions
Longhorn v1.2.x and v1.3.x versions
Scenario
In the past, you had a Rancher v2.5.x instance running. This Rancher instance was managing a few downstream clusters. In one of the downstream clusters, you installed Longhorn using the old Rancher UI (the App Catalog UI) as shown in the below picture:
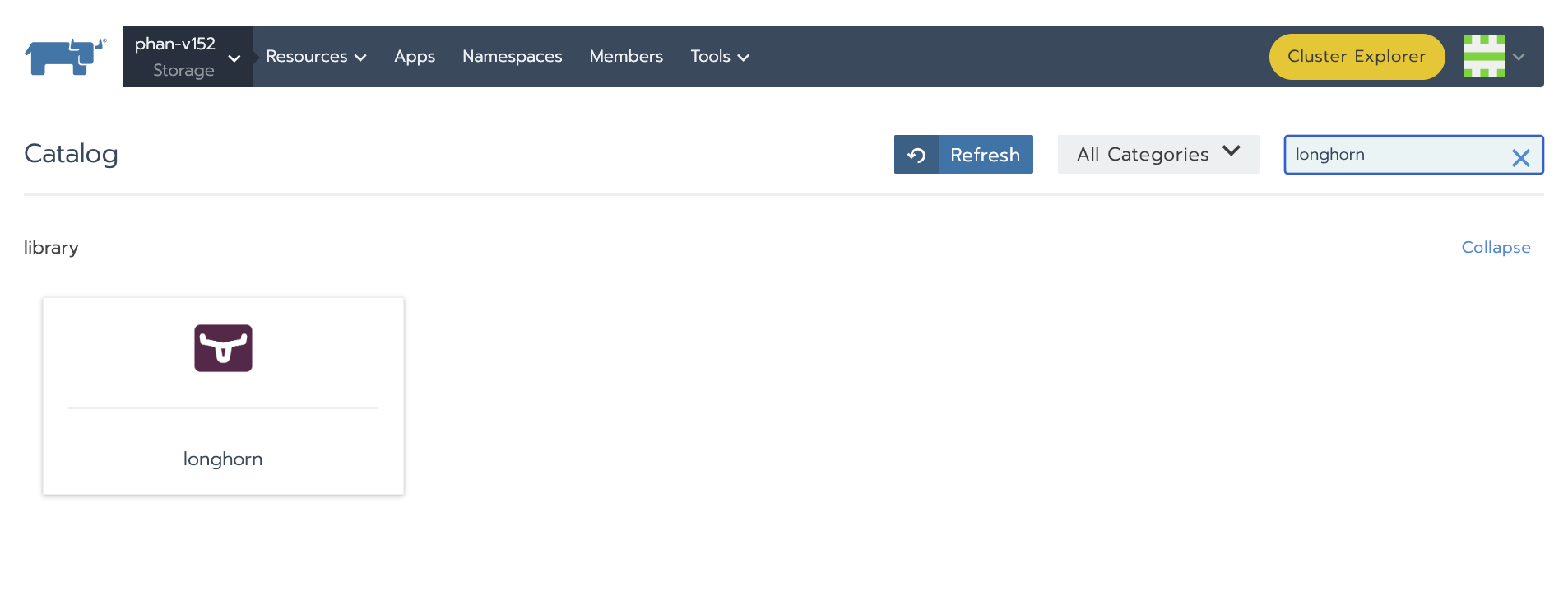
Now, you have already upgraded Rancher to the version >= v2.6.3. In this new Rancher version, a new UI, App & Marketplace, was introduced to replace the old App Catalog UI. Rancher hasn’t removed the App Catalog UI completely yet. You can still find your old Longhorn installation by going to Downstream Cluster -> Legacy -> Project -> select the correct project name from the dropdown on the top -> Apps. For example:
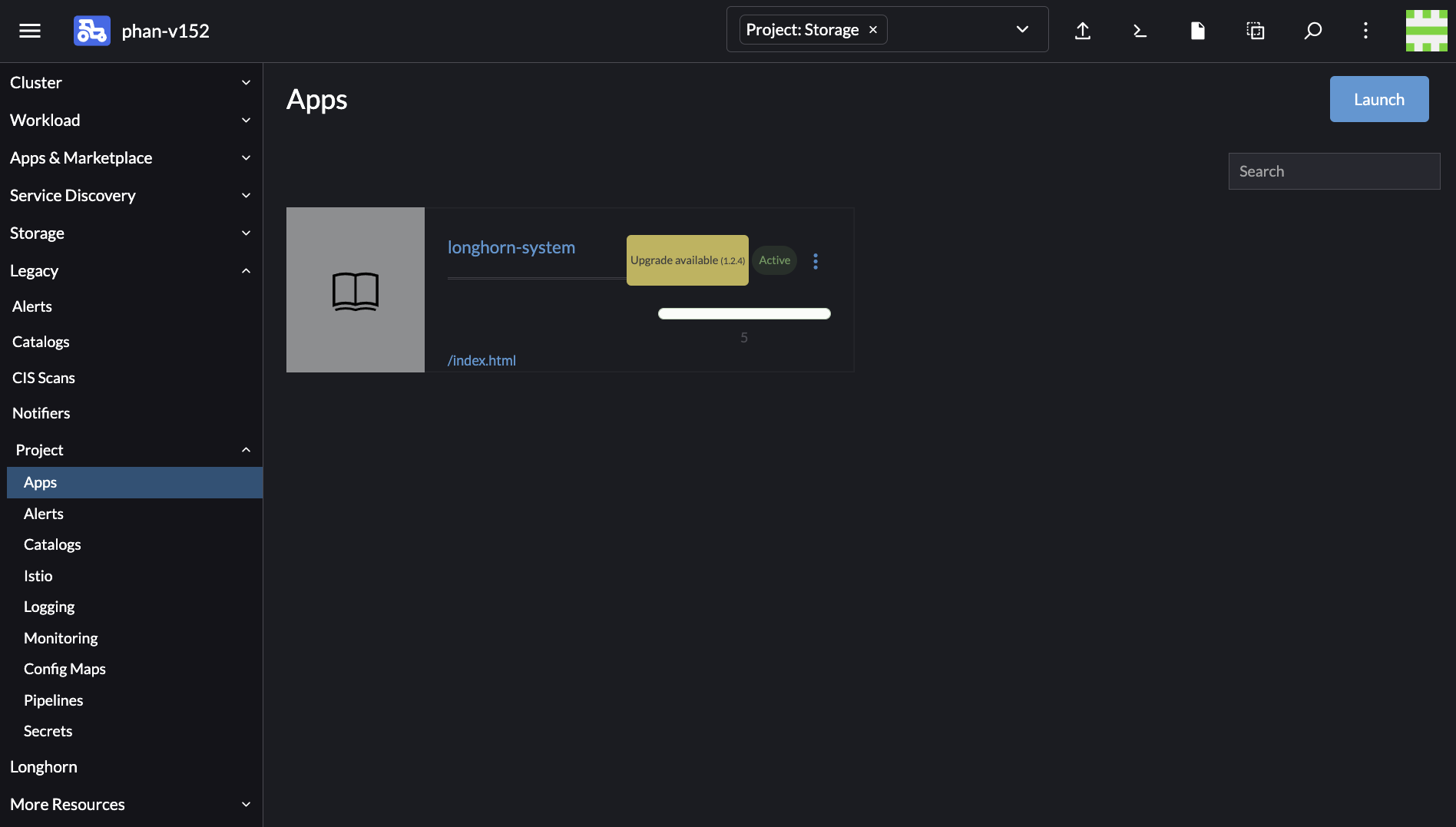
At this moment, there are 2 different Longhorn charts. One is in the App Catalog UI (you already installed Longhorn using this chart). The other one in the App & Marketplace (you have not installed Longhorn using this chart) as below:
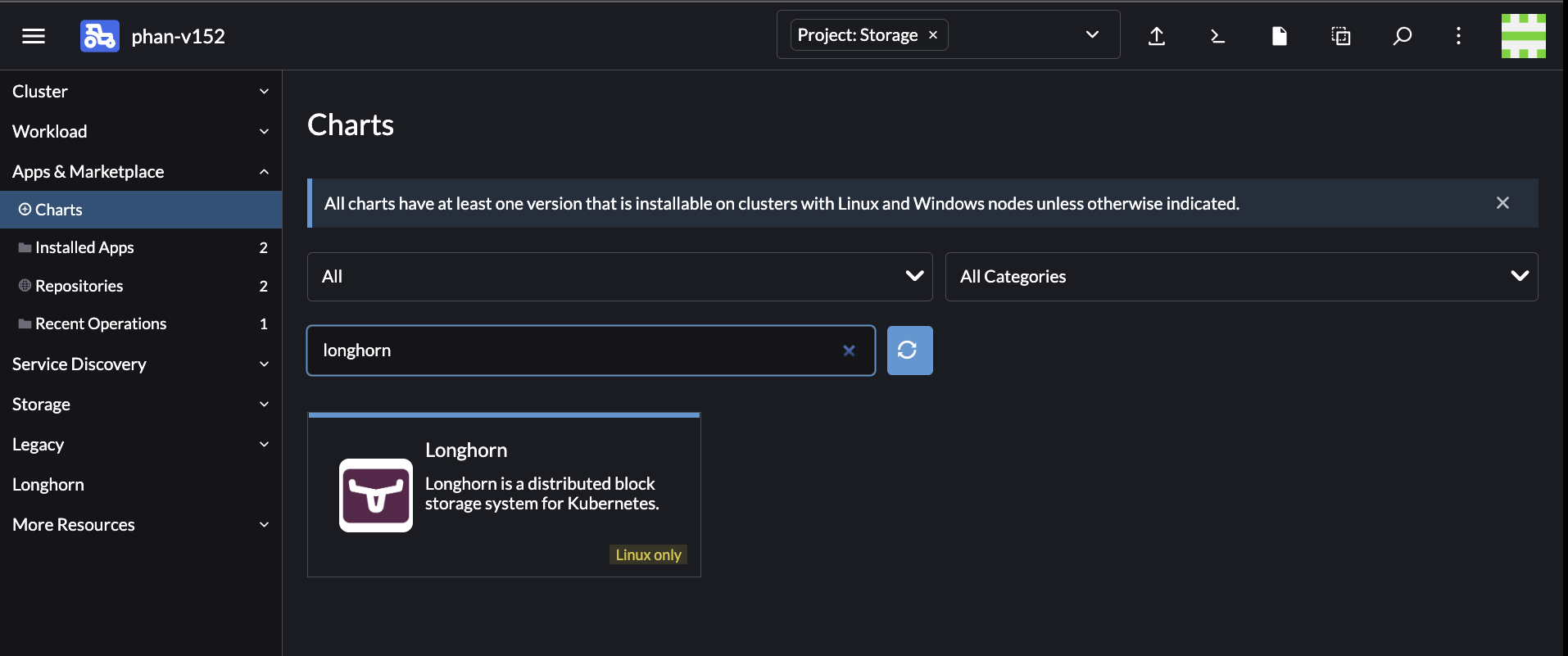
Because the App Catalog UI is being deprecated, you may want to migrate the existing Longhorn installation to the Longhorn chart in the App & Marketplace UI. The reason is Longhorn is planing to stop releasing new versions in the App Catalog UI in the future.
Prerequisites
- Longhorn v1.2.x and v1.3.x versions
- Rancher >= v2.6.3 versions
- The command kubectl get-all is available on your local machine
- The script longhorn_rancher_chart_migration.sh
Steps
- Go to Longhorn UI -> Settings -> General -> Change Concurrent Automatic Engine Upgrade Per Node Limit setting to 0 to disable auto engine upgrade.
(We need to do this because the migration process will involve updating the engine image to a new one that has an identical git commit but a different tag.
Upgrading the engine image for volumes in this case will cause the volumes to be stuck in upgrading).
If you don’t want to use Longhorn UI, you can change the setting by
kubectl edit settings.longhorn.io -n longhorn-system concurrent-automatic-engine-upgrade-per-node-limit - Download the kubeconfig file for the upstream rancher cluster (the kubeconfig file of the cluster on which the rancher instance is running on). Download the kubeconfig file for the downstream cluster where Longhorn is running on.
- Run the script
longhorn_rancher_chart_migration.shwith the flag--type migrate. E.g.,./longhorn_rancher_chart_migration.sh -u /path/to/upstream/rancher/cluster/kubeconfig -d /path/to/downstream/cluster/kubeconfig --type migrate". This script will update the annotations and labels for Longhorn resources so that Helm3 can adopt them. A sample of running output is:longhorn_rancher_chart_migration.sh -u /home/peterle/.kube/local -d /home/peterle/.kube/v154 Looking up Rancher Project App 'longhorn-system' ... Rancher Project App 'longhorn-system' found: Project-Namespace: p-v2lzv Catalog: library Template: longhorn (1.2.3) Answers: enablePSP=true,image.defaultImage=true,ingress.enabled=false,longhorn.default_setting=false,persistence.backingImage.enable=false,persistence.defaultClass=true,persistence.defaultClassReplicaCount=3,persistence.reclaimPolicy=Delete,persistence.recurringJobSelector.enable=false,persistence.recurringJobs.enable=false,privateRegistry.registryPasswd=,privateRegistry.registrySecret=,privateRegistry.registryUrl=,privateRegistry.registryUser=,service.ui.type=Rancher-Proxy Looking up existing Resources ... Patching CRD Resources ... customresourcedefinition.apiextensions.k8s.io/backingimagedatasources.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/backingimagedatasources.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/backingimagemanagers.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/backingimagemanagers.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/backingimages.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/backingimages.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/backups.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/backups.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/backuptargets.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/backuptargets.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/backupvolumes.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/backupvolumes.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/engineimages.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/engineimages.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/engines.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/engines.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/instancemanagers.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/instancemanagers.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/nodes.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/nodes.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/recurringjobs.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/recurringjobs.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/replicas.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/replicas.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/settings.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/settings.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/sharemanagers.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/sharemanagers.longhorn.io unlabeled customresourcedefinition.apiextensions.k8s.io/volumes.longhorn.io annotated customresourcedefinition.apiextensions.k8s.io/volumes.longhorn.io unlabeled Patching Other Resources ... clusterrolebinding.rbac.authorization.k8s.io/longhorn-bind annotated clusterrolebinding.rbac.authorization.k8s.io/longhorn-bind unlabeled clusterrole.rbac.authorization.k8s.io/longhorn-role annotated clusterrole.rbac.authorization.k8s.io/longhorn-role unlabeled configmap/longhorn-default-setting annotated configmap/longhorn-default-setting unlabeled configmap/longhorn-storageclass annotated configmap/longhorn-storageclass unlabeled daemonset.apps/longhorn-manager annotated daemonset.apps/longhorn-manager unlabeled deployment.apps/longhorn-driver-deployer annotated deployment.apps/longhorn-driver-deployer unlabeled deployment.apps/longhorn-ui annotated deployment.apps/longhorn-ui unlabeled endpointslice.discovery.k8s.io/longhorn-backend-frcmf annotated endpointslice.discovery.k8s.io/longhorn-backend-frcmf unlabeled endpointslice.discovery.k8s.io/longhorn-engine-manager-l46gt annotated endpointslice.discovery.k8s.io/longhorn-engine-manager-l46gt unlabeled endpointslice.discovery.k8s.io/longhorn-engine-manager-ndvd2 annotated endpointslice.discovery.k8s.io/longhorn-engine-manager-ndvd2 unlabeled endpointslice.discovery.k8s.io/longhorn-frontend-wfnxn annotated endpointslice.discovery.k8s.io/longhorn-frontend-wfnxn unlabeled endpointslice.discovery.k8s.io/longhorn-replica-manager-5zf97 annotated endpointslice.discovery.k8s.io/longhorn-replica-manager-5zf97 unlabeled endpointslice.discovery.k8s.io/longhorn-replica-manager-ps2sk annotated endpointslice.discovery.k8s.io/longhorn-replica-manager-ps2sk unlabeled endpoints/longhorn-backend annotated endpoints/longhorn-backend unlabeled endpoints/longhorn-engine-manager annotated endpoints/longhorn-engine-manager unlabeled endpoints/longhorn-frontend annotated endpoints/longhorn-frontend unlabeled endpoints/longhorn-replica-manager annotated endpoints/longhorn-replica-manager unlabeled podsecuritypolicy.policy/longhorn-psp annotated podsecuritypolicy.policy/longhorn-psp unlabeled rolebinding.rbac.authorization.k8s.io/longhorn-psp-binding annotated rolebinding.rbac.authorization.k8s.io/longhorn-psp-binding unlabeled role.rbac.authorization.k8s.io/longhorn-psp-role annotated role.rbac.authorization.k8s.io/longhorn-psp-role unlabeled serviceaccount/longhorn-service-account annotated serviceaccount/longhorn-service-account unlabeled service/longhorn-backend annotated service/longhorn-backend unlabeled service/longhorn-engine-manager annotated service/longhorn-engine-manager unlabeled service/longhorn-frontend annotated service/longhorn-frontend unlabeled service/longhorn-replica-manager annotated service/longhorn-replica-manager unlabeled ----------------------------- Successfully updated the annotations and labels for the resources! Next step: 1. Go to Rancher UI -> Go to the downstream cluster -> App&Marketplace -> Charts 2. Find and select the Longhorn chart 3. Select the chart version corresponding the Longhorn version 1.2.3 4. Install the chart with the correct helm values. Here are the helm values of your old charts: enablePSP=true,image.defaultImage=true,ingress.enabled=false,longhorn.default_setting=false,persistence.backingImage.enable=false,persistence.defaultClass=true,persistence.defaultClassReplicaCount=3,persistence.reclaimPolicy=Delete,persistence.recurringJobSelector.enable=false,persistence.recurringJobs.enable=false,privateRegistry.registryPasswd=,privateRegistry.registrySecret=,privateRegistry.registryUrl=,privateRegistry.registryUser=,service.ui.type=Rancher-Proxy 5. Verify that the migrated charts are working ok 6. Run this script again with the flag --type cleanup to remove the old chart from the legacy UI - Go to Rancher UI -> Go to the downstream cluster -> App&Marketplace -> Charts -> Find and select Longhorn chart -> Select the chart version corresponding to the correct Longhorn version -> Install the chart with the correct helm values. Note that all this detailed information is printed out at the end output of the above script.
- Verify that the migrated chart (in Rancher UI -> Downstream Cluster -> App & Marketplace -> Installed Apps) is working ok. E.g., check all Longhorn resources inside the namespace
longhorn-system, try to scale up and down workload to attach/detach Longhorn volumes, … - At this point the chart is migrated. However, you may notice that the old installation is still visible inside the legacy section:
- To remove the legacy icon without affecting Longhorn, you can run
longhorn_rancher_chart_migration.shscript with the flag--type cleanup. E.g.,./longhorn_rancher_chart_migration.sh -u /path/to/upstream/rancher/cluster/kubeconfig -d /path/to/downstream/cluster/kubeconfig --type cleanup. Note that you must NOT delete the chart directly from the UI because doing so would remove the resource of the newly migrated chart. You must run the script instead. An example of the output of running the script is:./longhorn_rancher_chart_migration.sh -u /home/peterle/.kube/local -d /home/peterle/.kube/v154 --type cleanup Looking up Rancher Project App 'longhorn-system' ... Rancher Project App 'longhorn-system' found: Project-Namespace: p-v2lzv Catalog: library Template: longhorn (1.2.3) Patching Project App Catalog ... app.project.cattle.io/longhorn-system patched Deleting Project App Catalog ... app.project.cattle.io "longhorn-system" deleted - The migration is fully completed.
Notes
- At this moment, even though Longhorn UI shows a new engine image version is available, you should not upgrade the engine image for volumes because the new engine image has an identical git commit. Upgrading the engine image for volumes in this case will cause the volumes to be stuck in upgrading. If you accidentally upgrade engine image you can try to scale down/up the workload pod, Longhorn will detach and reattach the volumes and the volumes will get out of the stuck state.
- You can try to upgrade Longhorn to a newer version using the new chart in App & Marketplace. This should work ok.
At this point, you can go ahead and re-enable the
Concurrent Automatic Engine Upgrade Per Node Limitsetting or manually upgrade the engine image for volume to the newer engine image.
Related Information
- Longhorn GitHub issue: https://github.com/longhorn/longhorn/issues/3714
Recent articles