Applicable versions
- All Longhorn v1.1.x versions
- Longhorn v1.2.x that are < v1.2.6
- Longhorn v1.3.x that are < v1.3.2
Symptoms
After a replica rebuilding, filesystem inside Longhorn volume is corrupted and cannot be mounted automatically. The workload pod that is using Longhorn volume has error event similar to:
Warning FailedMount 30s (x7 over 63s) kubelet MountVolume.SetUp failed for volume "pvc-bb8582d5-eaa4-479a-b4bf-328d1ef1785d" : rpc error: code = Internal desc = 'fsck' found errors on device /dev/longhorn/pvc-bb8582d5-eaa4-479a-b4bf-328d1ef1785d but could not correct them: fsck from util-linux 2.31.1
ext2fs_check_if_mount: Can't check if filesystem is mounted due to missing mtab file while determining whether /dev/longhorn/pvc-bb8582d5-eaa4-479a-b4bf-328d1ef1785d is mounted.
/dev/longhorn/pvc-bb8582d5-eaa4-479a-b4bf-328d1ef1785d contains a file system with errors, check forced.
/dev/longhorn/pvc-bb8582d5-eaa4-479a-b4bf-328d1ef1785d: Inodes that were part of a corrupted orphan linked list found.
/dev/longhorn/pvc-bb8582d5-eaa4-479a-b4bf-328d1ef1785d: UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY.
(i.e., without -a or -p options)
Related GitHub Tickets
Main ticket
Other related tickets
- https://github.com/longhorn/longhorn/issues/2330
- https://github.com/longhorn/longhorn/issues/3597
- https://github.com/longhorn/longhorn/issues/3895
- https://github.com/longhorn/longhorn/issues/3999
- https://github.com/longhorn/longhorn/issues/4000
- https://github.com/longhorn/longhorn/issues/4070
Root Cause Analysis
The root cause is a bug in copy-on-write mechanism when filesystem block size is not aligned with the 4096-byte IO size of Longhorn engine during replica rebuilding.
The below illustration shows how an ext4 filesystem with 1024-byte block size is being corrupted during the replica rebuilding process.
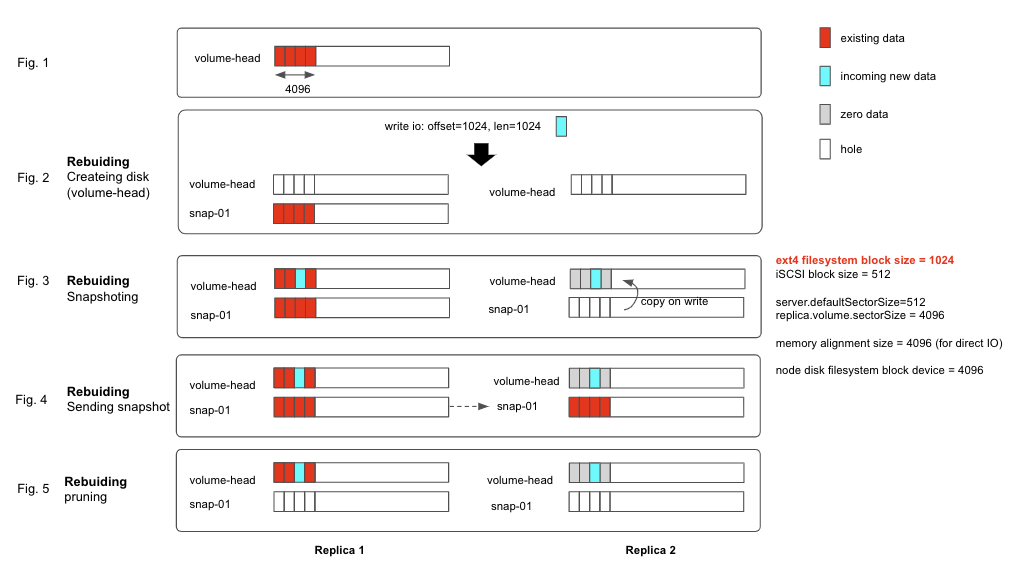
Fig 1:
Let’s say that the volume has 1 replica initially and have 4k data in the volume head at the first 4k block. Also, assume that volume has number of desired replica count is 2.
Fig 2:
Longhorn starts rebuilding the new replica by taking a new snapshot in both source replica and new replica: link
Fig 3:
Notice that the snap-01 is the newly taken snapshot from step 2.
At this moment, snap-01 in source replica has the initial data and snap-01 in the new replica is empty.
Longhorn marks the new replica as WO and starts allowing write IO to flow into both replicas.
In the background, an asynchronous process (the sync agent) will gradually copy the data of snap-01 from source replica to new replica.
Let’s say that there is a new write IO (offset=1024, length=1024) comes in before the sync agent finishes copying the data over.
Because the incoming IO size (1k) is smaller than the Longhorn engine IO size (4k), it triggers copy-on-write mechanism, link, so that:
- In the source replica’s volume-head:
- [0-1024) segment contains existing data
- [1024-2048) segment contains incoming new data
- [2048-4096) segment contains existing data
- In the new replica’s volume-head:
- [0-1024) segment contains zeroed data
- [1024-2048) segment contains incoming new data
- [2048-4096) segment contains zeroed data
As you can see that, the volume-head of the replicas is diverged from this point. The volume-head of the source replica contains the correct data. However, the new replica contains the wrong zeroed bytes data.
Fig 4
The sync agent finishes copying the data of snap-01 from source replica to new replica.
Then Longhorn marks new replica as RW and allow the read IO to come from either any of the replicas.
When the filesystem issue a read IO (offset=0, length=1024) to the Longhorn volume, if the read IO is read from the newly rebuilt replica, it would contain wrongly zeroed byte data. For ext4 filesystem, the first block contains important information about filesystem structure. Corrupting this part leads to the filesystem corruption.
Fig 5
Longhorn does some cleanup steps to save space but it is not relevant to this bug.
Solution
During rebuilding (while we have WO replica), in the Fig 3 above, if the incoming write IO is not 4096-byte aligned, we read full 4096-byte blocks from RW replicas (the source replica)then write that to all replicas. The PR for this solution is at https://github.com/longhorn/longhorn-engine/pull/745 and https://github.com/longhorn/longhorn-engine/pull/759
Furthermore, you might have noticed that copy-on-write mechanism is expensive as it requires an additional read as well as IO serialization by locking here. COW is triggered when filesystem block size is non-4096-byte. Therefore, we modify Longhorn CSI plugin to make filesystem with 4096-byte block size by default. This helps to avoid triggering COW and thus improve the performance. The PR for this solution is at https://github.com/longhorn/longhorn-manager/pull/1495
Other considered Proposal
Right now, Longhorn engine internally works with 4096-byte block size, but Longhorn device is external advertised as 512-byte physical block size
(i.e., running blockdev --getpbsz /dev/longhorn/<longhorn-volume-name> returns 512).
This 512-byte physical block size suggest mkfs that it is ok to create filesystem with smaller than 4096-byte block size. However, non-4096-byte filesystem triggers COW mechanism and affects performance.
We were thinking to advertise Longhorn device as 4096-byte physical block size to resolve that above issue. However, we decided not use this approach because:
- Backward compatibility: existing Longhorn volumes with non-4096-byte filesystem block size cannot mount if Longhorn engine change advertised physical block size to 4096 byte.
- Backing image volumes: many official OS base images are using XFS which has non-4096-byte block size for metadata by default. As the result, if Longhorn engine advertises physical block size as 4096-byte, these base images cannot work.
Reproducing/Testing Steps
Reproducing steps:
Mounting script:
DEV=/dev/longhorn/<volume-name>
for i in {1..20000}
do
echo $i
date
umount /mnt
mount "$DEV" /mnt
if [ $? != 0 ]; then
exit 1
fi
sleep 0.1
done
Deploy any Longhorn version < master
Case 1: ext4 filesystem with 1024 byte block size
- Create a Longhorn volume of 1 replica 1GB.
- Attach it to a node
- Format the block device
mkfs.ext4 /dev/longhorn/<volume-name> -b 1024 - Run the above
mounting scriptwith the correct block device - Scale up the number of replicas from 1 to 2
- Verify that the filesystem is broken (if not, delete a replica to trigger rebuilding. It should happen after 2-3 rebuilding)
Case 2: xfs filesystem with 512 byte block size
- Create a Longhorn volume of 1 replica 1GB.
- Attach it to a node
- Format the block device
mkfs.xfs /dev/longhorn/<volume-name> - Check the xfs filesystem and make sure that the meta data blocksize is 512 bytes. E.g.:
ip-10-0-2-15:/ # xfs_info /dev/longhorn/testvol2 meta-data=/dev/longhorn/testvol2 isize=512 agcount=4, agsize=32000 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=0, rmapbt=0 = reflink=0 data = bsize=4096 blocks=128000, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=855, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 - Run the above
mounting scriptwith the correct block device - Scale up the number of replicas from 1 to 2
- Verify that the filesystem is broken (if not, delete a replica to trigger rebuilding. It should happen after 2-3 rebuilding)
Case 3: backing image with xfs filesystem with 512 byte block size
- Create a backing image from URL
https://cloud.centos.org/centos/7/images/CentOS-7-x86_64-GenericCloud-2111.qcow2 - Create a Longhorn volume of 1 replica of 10GB with the above backing image
- Attach it to a node
- Find the major and minor version of the block device by
ls -l /dev/longhorn/<volume-name> - Find the corresponding block device under
lsblkwith the same major and minor version. Then find the root partition of that block device - Check the xfs filesystem of the root partition and make sure that the meta data blocksize is 512 bytes. E.g.:
ip-10-0-2-15:/ # xfs_info /dev/longhorn/testvol2 meta-data=/dev/longhorn/testvol2 isize=512 agcount=4, agsize=32000 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=0, rmapbt=0 = reflink=0 data = bsize=4096 blocks=128000, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=855, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 - Run the above
mounting scriptwith the correct block device/dev/.../<root-partition-name> - Scale up the number of replicas from 1 to 2
- Verify that the filesystem is broken (if not, delete a replica to trigger rebuilding. It should happen after 2-3 rebuilding)
Testing steps:
Rerun the above steps with master-head and verify that you cannot corrupt the filesystem
Recent articles