Support for ReadWriteMany (RWX) workloads
Longhorn supports RWX workloads via the nfs.longhorn.io provisioner.
The following diagram shows how the RWX support works:
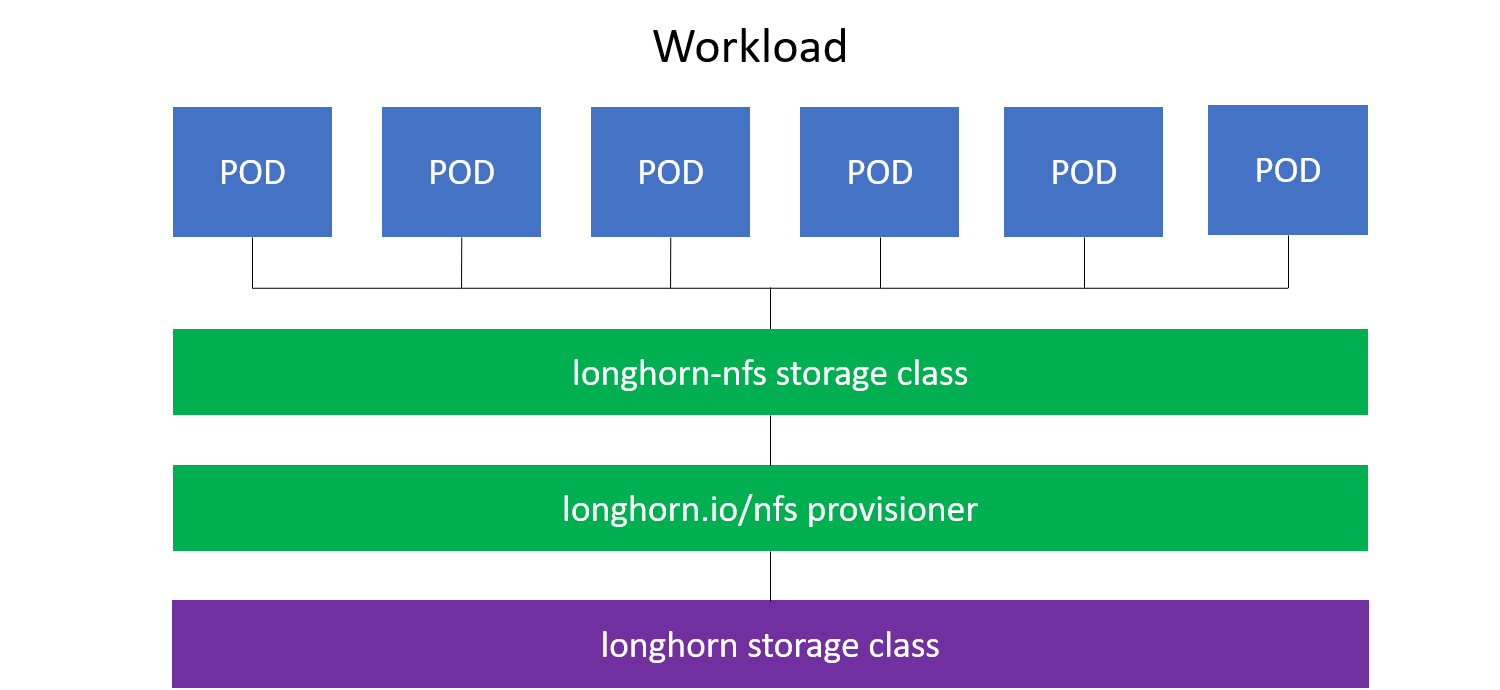
Enabling RWX Support
To enable RWX support you need to deploy the following files:
The 03-rwx-test.yaml example deployment has four pods that share an RWX volume via NFS mounted at /mnt/nfs-test. Every second the pods append the current date and time to a shared log file under /mnt/nfs-test/test.log.
In the default configuration we provision a 20Gb Longhorn volume as a backing volume for the RWX workload. We suggest you set that to your required capacity before deploying 02-longhorn-nfs-provisioner.yaml.
The requested size should be roughly 10% bigger then the required RWX workload size.
It’s important to note that one can only run a single nfs-provisioner instance per StorageClass. It would be incorrect to increase the replica count for the nfs-provisioner. Instead read below to see how to deploy additional nfs-provisioners.
It’s possible to provision multiple RWX volumes from a single nfs-provisioner, but the workloads would share the underlying Longhorn backing storage.
Multiple RWX Workloads
If you want to run multiple RWX volumes, consider creating different nfs-provisioner deployments.
You can modify the provisioner argument and create a new StorageClass for that provisioner. For an example, see 02-longhorn-nfs-provisioner.yaml.
You could call the new provisioner nfs.longhorn.io/2 and the StorageClass longhorn-nfs2. Afterwards create a new service longhorn-nfs-provisioner2 with a random unique cluster-ip and update the SERVICE_NAME environment variable to point to your new service. The different provisioners can share the same security setup from 01-security.yaml.

Failure handling
Service Cluster IP
For the longhorn-nfs-provisioner service we hardcode the service IP to 10.43.111.111.
If this IP is not available on your cluster (in use, outside of network range) you can choose any other random unique IP. We recommend hardcoding a random unique cluster IP since the PVCs will end up with this hardcoded service IP after creation.
Node Failure
In the case of a node failure, a replacement longhorn-nfs-provisioner pod should be available after roughly 90 seconds.
We use the following tolerations to decide when to evict the nfs-provisioner pod. You can lower the tolerationSeconds
to lower the nfs-provisioner failover time in the case of a node failure.
We recommend setting up a liveness probe on your RWX workloads. The failing liveness probe will lead to a pod restart that will make the RWX volume available again, once the replacement nfs-provisioner is up and running.
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 60
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 60
Workload Health Check
We recommend the setup of a liveness check on the workloads that makes sure the pods get restarted on NFS server failures.
Example liveness probe: timeout 10 ls /mnt/nfs-mountpoint.
We need to include the timeout command as part of the liveness check to work around this Kubernetes issue.
© 2019-2026 Longhorn Authors | Documentation Distributed under CC-BY-4.0
© 2026 The Linux Foundation. All rights reserved. The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our Trademark Usage page.