Support for ReadWriteMany (RWX) workloads (Experimental Feature)
Longhorn natively supports RWX workloads, by exposing a regular Longhorn volume via a NFSv4 server (share-manager).
The following diagram shows how the RWX support works:
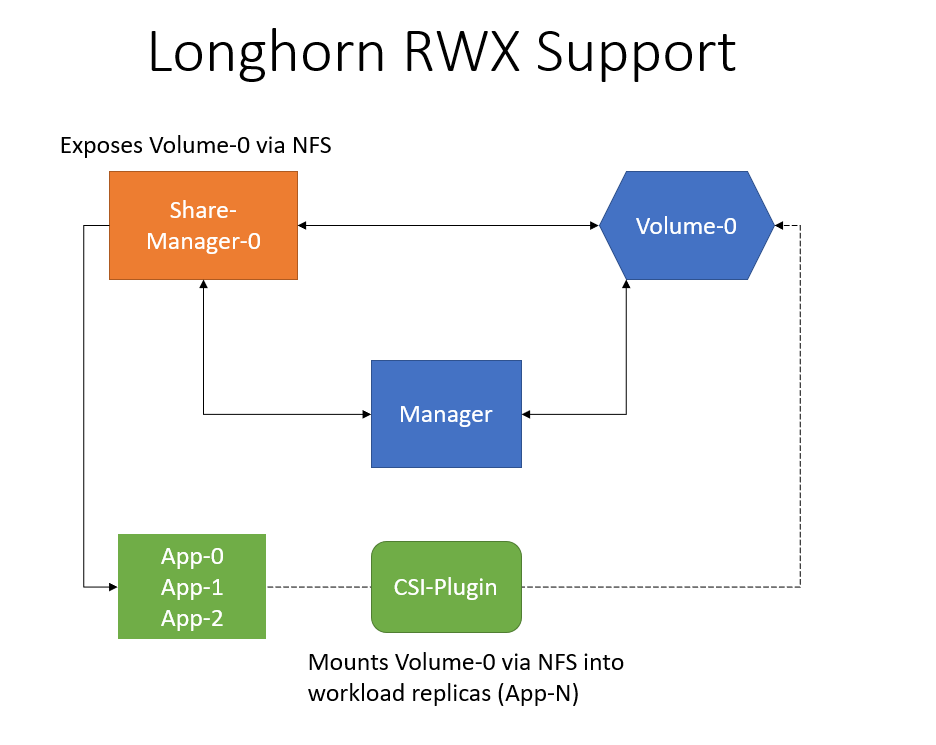
For each actively in use RWX volume Longhorn will create a share-manager-<volume-name> Pod in the longhorn-system namespace.
This Pod is responsible for exporting a Longhorn volume via a NFSv4 server that is running inside the Pod.
There is also a service created for each RWX volume, and that is used as an endpoint for the actual NFSv4 client connection.
Requirements
To be able to use RWX volumes, each client node needs to have a NFSv4 client installed. Please refer to Installing NFSv4 client for more installation details.
If the NFSv4 client is not available on the node, when trying to mount the volume the below message will be part of the error:
for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program.\n
Creation and Usage of a RWX Volume
For dynamically provisioned Longhorn volumes, the access mode is based on the PVC’s access mode.
For manually created Longhorn volumes (restore, DR volume) the access mode can be specified during creation in the Longhorn UI.
When creating a PV/PVC for a Longhorn volume via the UI, the access mode of the PV/PVC will be based on the volume’s access mode.
One can change the Longhorn volume’s access mode via the UI as long as the volume is not bound to a PVC.
For a Longhorn volume that gets used by a RWX PVC, the volume access mode will be changed to RWX.
Failure Handling
Any failure of the share-manager Pod (volume failure, node failure, etc) will lead to the Pod being recreated and the volume’s remountRequestedAt flag to be set, which will lead to the workload Pods being deleted and Kubernetes
recreating them. This functionality depends on the setting of Automatically Delete Workload Pod when The Volume Is Detached Unexpectedly,
which by default is true. If the setting is disabled, the workload Pods might end up with io errors on RWX volume failures.
It’s recommended to enable the above settings to guarantee automatic workload failover in the case of issues with the RWX volume.
Migration from Previous External Provisioner
The below PVC creates a Kubernetes job that can copy data from one volume to another.
- Replace the
data-source-pvcwith the name of the previous NFSv4 RWX PVC that was created by Kubernetes. - Replace the
data-target-pvcwith the name of the new RWX PVC that you wish to use for your new workloads.
You can manually create a new RWX Longhorn volume + PVC/PV, or just create a RWX PVC and then have Longhorn dynamically provision a volume for you.
Both PVCs need to exist in the same namespace. If you were using a different namespace than the default, change the job’s namespace below.
apiVersion: batch/v1
kind: Job
metadata:
namespace: default # namespace where the PVC's exist
name: volume-migration
spec:
completions: 1
parallelism: 1
backoffLimit: 3
template:
metadata:
name: volume-migration
labels:
name: volume-migration
spec:
restartPolicy: Never
containers:
- name: volume-migration
image: ubuntu:xenial
tty: true
command: [ "/bin/sh" ]
args: [ "-c", "cp -r -v /mnt/old /mnt/new" ]
volumeMounts:
- name: old-vol
mountPath: /mnt/old
- name: new-vol
mountPath: /mnt/new
volumes:
- name: old-vol
persistentVolumeClaim:
claimName: data-source-pvc # change to data source PVC
- name: new-vol
persistentVolumeClaim:
claimName: data-target-pvc # change to data target PVC
History
- Available since v1.0.1 External provisioner
- Available since v1.1.0 Native RWX support
© 2019-2025 Longhorn Authors | Documentation Distributed under CC-BY-4.0
© 2025 The Linux Foundation. All rights reserved. The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our Trademark Usage page.