Introduction
Longhorn is an official CNCF project that delivers a powerful cloud-native distributed storage platform for Kubernetes that can run anywhere. Longhorn makes the deployment of highly available persistent block storage in your Kubernetes environment easy, fast, and reliable.
Since the Longhorn v1.0.0 release, we’ve received many queries regarding the performance and scalability aspects of Longhorn. We’re glad to share some results here.
Performance
Environment setup
Benchmark software
We’re using a forked version of dbench, which uses fio to benchmark Kubernetes persistent disk volumes. It collects the data regarding read/write IOPS, bandwidth and latency.
Hardware Environment
We built a Kubernetes cluster using AWS EC2 instances.
One note on the disks: we’re using the EC2 instance store for the benchmark, which is located on disks that are physically attached to the host computer. It can provide better performance in comparison to EBS volume, especially in terms of IOPS.
Instance spec:
c5d.2xlarge
Disk: 200 GiB NVMe SSD as the instance store.
CPU: 8 vCPUs (Intel(R) Xeon(R) Platinum 8124M CPU @ 3.00GHz)
Memory: 16 GB
Network: Up to 10Gbps
Kubernetes setup:
3 nodes.
All nodes are both master and worker nodes.
Software Environment
Kubernetes: v1.17.5.
Node OS: 5.3.0-1023-aws #25~18.04.1-Ubuntu SMP
Longhorn: v1.0.1
Benchmark Result
Bandwidth
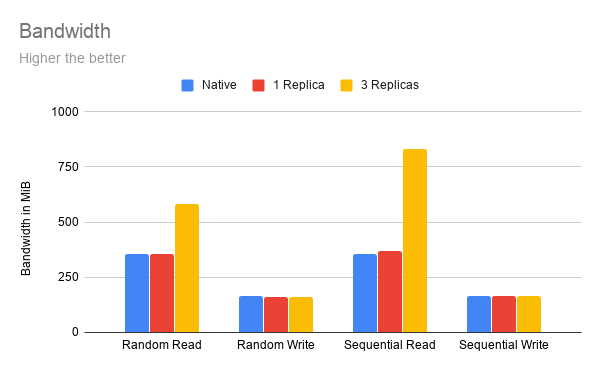
As you can see in the diagram above:
With 1 replica, Longhorn provides the same bandwidth as the native disk.
With 3 replicas, Longhorn provides 1.5 times to 2+ times performance compared to a single native disk. This is because Longhorn uses multiple replicas on different nodes and disks in response to the workload’s request.
IOPS and Latency
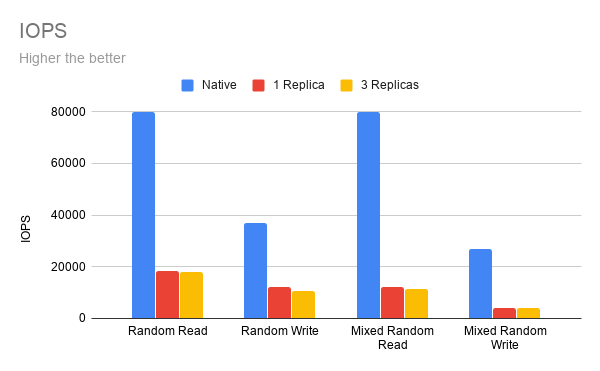
As you can see in the IOPS diagram above, Longhorn provides 20% to 30% IOPS of the native disk.
One of the reasons for the lower IOPS is because Longhorn is designed to be crash consistent across the cluster. The data sent to a Longhorn volume will be replicated to replicas on different nodes in a synchronized way. Longhorn will wait for the confirmation that the data has been written to every replica’s disk before continuing. This makes sure in the event of losing any replica, the other replicas will still have the up-to-date data.
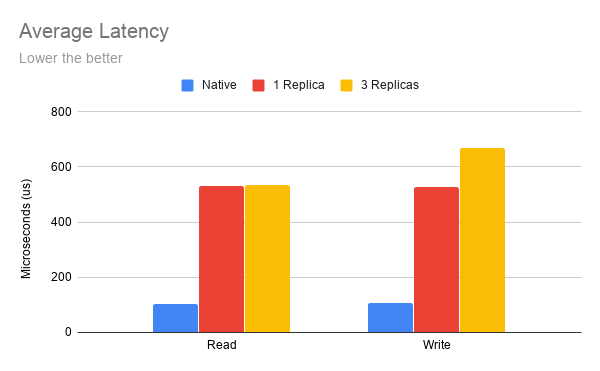
As you can see from the latency diagram, the native disk’s IO latency is about 100 microseconds per IO operation in our benchmark. Longhorn adds another 400 microseconds to 500 microseconds on top of it, depending on how many replicas are used and if the operation is read or write.
We continue working on the performance optimization to reduce the latency introduced by the Longhorn stack.
Scalability
Environment Setup
Hardware Environment
We built a Kubernetes cluster using AWS EC2 instances for the benchmark.
Instance spec:
m5.2xlarge
CPU: 8 vCPUs
Memory: 32 GB Memory
Kubernetes setup:
Master nodes: 3 Worker nodes: 100
Software Environment
Kubernetes: v1.18.6, installed using Rancher
Longhorn v1.0.1
Benchmark Method
We created 100 StatefulSets with a VolumeClaimTemplate that uses Longhorn.
Each of the 100 Nodes had one StatefulSet bound to it using a nodeSelector.
During the test, we scaled each StatefulSet to 10. Both the total Pod count and Longhorn Volume count at the end of testing was 1000.
Then every two minutes we checked how many Pods had been successfully started. All the Pods contain a LivenessProbe to guarantee the functionality of the Longhorn Volume.
Result

Result Analysis
As you can see from the diagram above, except for the first 100 nodes (which needs a bit more ramp-up time due to the image pull), the scalability of Longhorn is near-linear, until when we hit about 950 pods.
For the first 950 Pods with Longhorn Volumes, Kubernetes and Longhorn only spent about 1500 seconds (25 minutes) to spin them all up. However, for the remaining 50 Pods, it took another 1000 seconds (~17 minutes), which means the last 5% of the pods took about 40% of the time of the whole scalability test. We’re still looking into the reason. We haven’t determined if it’s a Kubernetes or Longhorn issue.
Other Issues during the Scalability Test
We encountered a couple of Kubernetes and Longhorn issues during the scalability testing:
- During a test run, we found that we cannot scale well after hitting 200 volumes in the cluster. After digging deeper into it, we found that it took minutes to tens of minutes for Kubernetes to recognize a newly attached volume after the cluster had more than 200 volumes. In the end, we found this was a Kubernetes bug and has been fixed in v1.17.8 and v1.18.5. See here for the full analysis.
- During the installation of Longhorn v1.0.1 in the cluster, we encountered a Longhorn issue that blocked the installation process. The issue will likely occur if the cluster is bigger than 20 nodes, and requires a manual workaround. We’re releasing a fix for the issue in v1.0.2 release. See here for the details.
Recent posts
What's New in Longhorn 1.11Strengthen Longhorn with Automated End-to-End Tests
V2 Disk Size Aggregation
What's New in Longhorn 1.10
Limit Volume Replica Actual Space Usage
Backup Applications with Longhorn V2 Volumes using Velero
What's New in Longhorn 1.9
Longhorn 1.4.1 released
What's New in Longhorn 1.4
Security Advisories for Longhorn CVE-2021-36779 & CVE-2021-36780
Welcome Longhorn 1.2
Longhorn at KubeCon NA 2021
Announcing Longhorn v1.1.0
Longhorn at KubeCon NA 2020
Longhorn at KubeCon EU 2020
Performance and Scalability Report for Longhorn v1.0